One of the interesting theories related to consciousness is The Simulation Theory of Consciousness concisely presented in [1]. According to the author, “… if a computer-based system uses inputs from one or more sensors to create an integrated dynamic model of its reality that it subsequently uses to control its actions, then that system is subjectively aware of its simulation. As long as its simulation executes, the system is conscious, and the dynamic contents of its simulation form its stream of consciousness…”
The book starts with the position that is very close to our OODA control loop perspective, but later in the book there is more emphasis on world modelling than on integration of sensing and acting.
“… Question: Is the simulation sufficient as well as necessary? Is the execution of the simulation by itself enough to generate subjective awareness of the simulation? Does the simulation have to be based on input from sense organs or sensors? …
Suspected answer: Yes. Anything that executes a simulation of reality is conscious, and the contents of its simulation form the contents of its stream of consciousness… Although sentient creatures evolved their simulations to enable them to make sense of sensory information and to control their behaviors, it is the simulation itself that creates consciousness, not their sense organs or their effector organs…” [1]
We share the main sentiment of this theory related to importance of the integrated dynamic model of ‘the reality’ for understanding consciousness (human, animal, other creatures or artificial). However, we believe it is a specific type of dynamic models of the reality embedded in the control OODA loop that matters.
Not every reality simulation has a potential for subjective experience. Let’s take a look at the idea of digital twin, for example. With our current and upcoming technologies we could easily picture dynamic digital model of our world from the human level perspective, with dynamic models for buildings, cars, trees, roads, etc. We would describe this digital twin as a running world model (built from the human centric perspective by design), but lacking any subjectivity. The same is true for world modelling in electronic games. However, the story could be different if we switch our conversation to world modelling in NPCs – non-player characters. With NPCs we have a choice how shallow/deep we want to model subjective experience similar to simulating perception in NPCs – “… Up until the mid-1990s, simulating sensory perception was rare (at most, a ray cast check was made to determine if line of sight existed). Since then, increasingly sophisticated models of sensory perception have been developed…” [2].
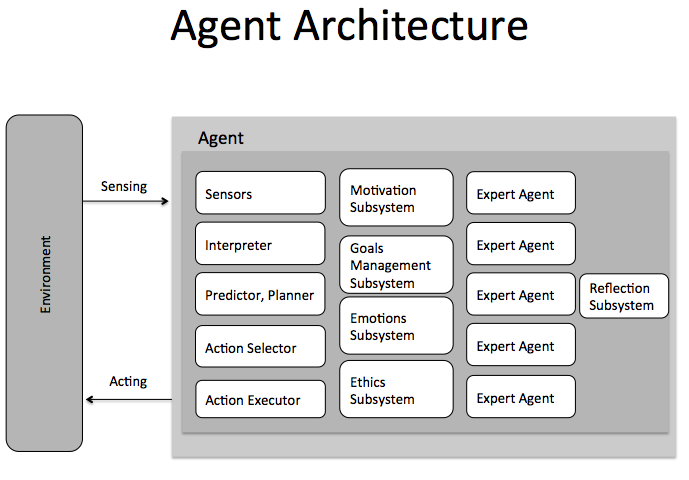
On the other side of the spectrum we could picture a system with the OODA loop and localized perception and actions. This localization means that the system has a model of a limited fragment of the environment at every moment and also has limited actions that could change the relationship between the environment and the system. We also would add the internal motivation sub-system based on feelings and homeostasis (multidimensional with additional aggregated “good/bad for me” dimension, inspired by [3]). Another important capability is attention – ability to concentrate perception on specific fragments of the environment and the system itself (inspired by [4,5]).
We believe that following properties are important for a basic system with simulated subjective experience:
- Each system has boundaries and runs its own world simulation as part of a OODA control loop
- Localized perception and action – a window to the world from the egocentric perspective
- Specific sensors (external and internal) and actions define (better to say intertwined with) system ‘reality’
- Input from sensors is used to create internal representations/models of the world and self
- Working memory
- Attention (as a way to change the window into external and internal world and keep it ‘active’ in working memory for some time until something more important comes into observation)
- Predictions as part of the OODA loop and some mechanism to evaluate predictions vs ‘reality’ (in basic cases it is probably embedded into architecture, innate, no learning required)
- Homeostasis with feelings (as a building block for intentionality, motivation, goals)
There is an interesting question about individual (per system) dynamic memory: episodic and semantic – is it important? It looks like individual memory could fundamentally enhance the ability for subjective experience (and intelligence, of course) but basics could be achieved with ‘memory’ embedded as part of a system architecture (innate) and working memory integrated with attention.
There are quite intriguing results coming from studying and modeling insects, for example, dragonflies [6]. It is fascinating because we are looking at basics, boundary cases of subjective experiences.
What about self-driving cars? They are engineering marvel even with current limitations and constraints. Does self-driving car have a subjective experience or at least an equivalent of subjective experience? The book suggests that ‘yes’, it does. We would say ‘it depends’. It is possible to build self-driving cars with deep modelling of subjective experience. If we look at the basic list above, self-driving cars do almost everything except probably simulation of feelings and motivation sub-system, although basic model of physical self is required. There is probably some equivalent of attention but it is most likely not modelled after human (or other creatures) attention directly.
We follow [3, 7] with including feelings and homeostasis as a very important part of simulating subjective experience.
In theory, we could explicitly add simulated feelings to self driving cars. But we probably should not. It is better to design a self-driving car as a ‘tool’ without simulating subjective experiences. The same is true for ‘smart’ refrigerators, TVs, ovens and millions of other objects. Adding simulated subjectivity into these devices would be a mistake… However, there is a huge potential for intelligent environments with built-in sensors and smart control loops (just without simulating subjective experiences)
We would reserve simulated subjective experience for special cases… such as J.A.R.V.I.S. and Mister Data.
[1] Firesmith, Donald. The Simulation Theory of Consciousness: (or Your Autonomous Car is Sentient).
[2] Millington, Ian. Artificial Intelligence for Games.
[3] Solms, Mark. The Hidden Spring: A Journey to the Source of Consciousness.
[4] Graziano, Michael S A. Rethinking Consciousness: A Scientific Theory of Subjective Experience.
[5] Prinz, Jesse J.. The Conscious Brain (Philosophy of Mind).
[6] Fast, Efficient Neural Networks Copy Dragonfly Brains, IEEE Spectrum, link
[7] Damasio, Antonio. Self Comes to Mind.